机器学习分类算法精要 从贝叶斯分类到AI基础软件开发
人工智能与机器学习基础
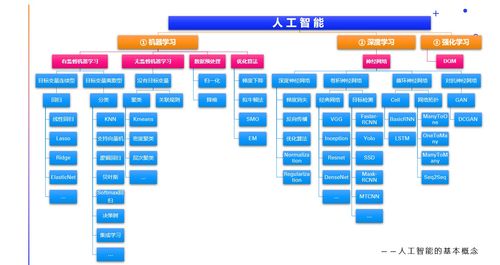
人工智能(AI)作为计算机科学的一个重要分支,旨在创造能够模拟人类智能的机器系统。在这一宏大领域中,机器学习作为核心实现手段,赋予了计算机从数据中学习和改进的能力,而无需依赖明确的程序指令。机器学习主要分为监督学习、无监督学习和强化学习三大类,其中分类任务是监督学习中最常见且应用最广泛的问题之一。
机器学习分类任务详解
分类任务的核心目标是根据已知标签的训练数据,构建一个模型,该模型能够准确地将新的、未见过的数据点分配到预定义的类别中。这好比教一个孩子识别动物:通过展示大量带有“猫”、“狗”标签的图片,孩子逐渐学会区分二者的特征,未来看到新动物时便能做出判断。
一个完整的分类流程通常包括数据收集与预处理、特征工程、模型选择与训练、模型评估与优化等步骤。特征工程是从原始数据中提取对分类有意义的属性,这一步的质量往往直接决定了模型性能的上限。
贝叶斯分类:概率论的智慧
在众多分类算法中,贝叶斯分类器以其坚实的概率论基础和直观的“逆概率”思想而独树一帜。其核心是贝叶斯定理:
P(A|B) = [P(B|A) * P(A)] / P(B)
在分类语境下,A代表类别,B代表观测到的特征。我们目标是计算在给定特征B的条件下,样本属于类别A的概率P(A|B),即后验概率。通过比较所有类别的后验概率,将样本分配给概率最大的类别。
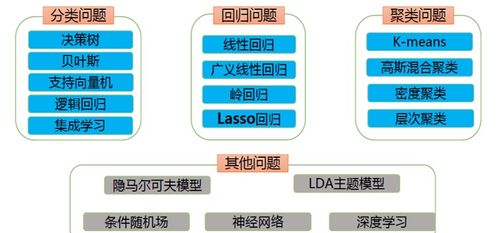
最著名的应用是朴素贝叶斯分类器。它做了一个关键的“朴素”假设:在给定类别的情况下,所有特征之间是相互独立的。这个假设虽然在现实中很少严格成立,却极大地简化了计算,并且在文本分类(如垃圾邮件过滤)、情感分析等领域表现出色,计算高效且对缺失数据不敏感。
贝叶斯方法的优势在于它提供了一个完整的概率框架,不仅能给出分类结果,还能给出分类的置信度(即概率本身)。其变体如高斯朴素贝叶斯、多项式朴素贝叶斯等,适用于不同类型的特征数据。
从算法到应用:人工智能基础软件开发
掌握分类算法是基础,而将其转化为稳定、可用的软件产品,则是人工智能赋能各行各业的关键。人工智能基础软件开发涉及一个完整的技术栈和工程化流程:
- 开发环境与工具链:通常使用Python作为主要语言,依托如NumPy、Pandas进行数据处理,Scikit-learn(内含朴素贝叶斯等多种分类器)进行模型构建,Matplotlib/Seaborn进行可视化。深度学习任务则可能使用TensorFlow或PyTorch。
- 软件架构设计:一个健壮的AI软件需要清晰的架构。例如,采用MVC(模型-视图-控制器)或其变体分离数据、逻辑与界面。核心的分类模型通常作为服务模块,通过定义良好的API(应用编程接口)与其他模块(如数据输入、结果展示、日志记录)交互。
- 工程化实践:
- 数据处理管道:构建可复用的数据加载、清洗、转换和特征提取流水线。
- 模型生命周期管理:包括模型的版本控制、序列化存储(如使用joblib或ONNX格式)、以及上线后的监控与定期再训练。
- 性能与可扩展性:对于大规模数据,需要考虑分布式计算框架(如Spark MLlib)。将模型部署为微服务,以便灵活扩展。
- 可解释性与调试:特别是对于医疗、金融等高风险领域,需要集成LIME、SHAP等工具来解释模型的预测依据,增加信任度。
- 从原型到部署:开发流程往往从Jupyter Notebook中的快速原型验证开始,随后将代码重构为模块化、可测试的工程代码。最终通过Docker容器化,部署到云服务器、边缘设备或嵌入式系统中。部署后还需建立持续集成/持续部署(CI/CD)管道,实现自动化测试与更新。
##
从理解人工智能的宏伟目标,到钻研机器学习分类的具体任务,再到深入贝叶斯分类的数学原理,最终落地于扎实的软件开发实践,这是一条从理论到应用的完整路径。以贝叶斯分类为代表的经典算法,因其简洁、高效和良好的概率解释性,在AI基础软件中依然占据着重要地位。未来的AI开发者,既需要深厚的算法功底,也需要精湛的软件工程能力,方能将智能的“火花”转化为驱动社会进步的“引擎”。
如若转载,请注明出处:http://www.omron-sh.com/product/51.html
更新时间:2026-02-24 14:54:24